DataFrame의 특징
- 2차원 구조: 행과 열로 구성됩니다.
- 다양한 데이터 타입: 각 열은 서로 다른 데이터 타입을 가질 수 있습니다.
- 레이블 인덱싱: 행과 열 모두 레이블 인덱싱을 지원합니다.
- 다양한 데이터 소스: 리스트, 딕셔너리, NumPy 배열, 외부 파일(CSV, Excel 등) 등 다양한 데이터 소스로부터 생성할 수 있습니다.
pandas DataFrame을 활용한 세 가지 예시 문제와 그 해결 방법입니다. 각 문제는 DataFrame의 생성, 접근, 조작 및 분석 방법을 익히는 데 도움이 됩니다.
예시 문제 1: DataFrame 생성 및 기본 조작
문제:
- 아래 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 이름: ['Alice', 'Bob', 'Charlie', 'David', 'Eva']
- 나이: [25, 30, 35, 40, 45]
- 성별: ['F', 'M', 'M', 'M', 'F']
- 데이터:
- '나이' 열의 평균을 구하세요.
- '성별'이 'M'인 행만 선택하여 출력하세요.
- '주소'라는 새로운 열을 추가하고 모든 값을 'Unknown'으로 설정하세요.

import pandas as pd
# 1. DataFrame 생성
data = {
'이름': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'나이': [25, 30, 35, 40, 45],
'성별': ['F', 'M', 'M', 'M', 'F']
}
df = pd.DataFrame(data)
print("DataFrame:\n", df)
# 2. '나이' 열의 평균 구하기
age_mean = df['나이'].mean()
print("\n나이의 평균:", age_mean)
# 3. '성별'이 'M'인 행 선택
male_rows = df[df['성별'] == 'M']
print("\n성별이 'M'인 행:\n", male_rows)
# 4. '주소' 열 추가
df['주소'] = 'Unknown'
print("\n'주소' 열 추가 후 DataFrame:\n", df)
예시 문제 2: DataFrame 필터링 및 그룹화
문제:
- 다음 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 제품: ['A', 'B', 'A', 'C', 'B', 'A']
- 가격: [100, 150, 100, 200, 150, 100]
- 수량: [1, 2, 3, 1, 2, 1]
- 데이터:
- 제품별 총 판매 금액(가격 * 수량)을 계산하여 새로운 열 '총 판매 금액'을 추가하세요.
- 제품별로 그룹화하여 각 제품의 총 판매 금액 합계를 구하세요.

import pandas as pd
# 1. DataFrame 생성
data = {
'제품': ['A', 'B', 'A', 'C', 'B', 'A'],
'가격': [100, 150, 100, 200, 150, 100],
'수량': [1, 2, 3, 1, 2, 1]
}
df = pd.DataFrame(data)
print("DataFrame:\n", df)
# 2. '총 판매 금액' 열 추가
df['총 판매 금액'] = df['가격'] * df['수량']
print("\n'총 판매 금액' 열 추가 후 DataFrame:\n", df)
# 3. 제품별 총 판매 금액 합계 구하기
grouped = df.groupby('제품')['총 판매 금액'].sum()
print("\n제품별 총 판매 금액 합계:\n", grouped)
예시 문제 3: 데이터 변형 및 정렬
문제:
- 아래 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 도시: ['서울', '부산', '인천', '대구', '대전']
- 인구: [10000000, 3500000, 3000000, 2500000, 1500000]
- 면적: [605, 770, 1063, 884, 539]
- 데이터:
- 인구 밀도(인구 / 면적)를 계산하여 '인구 밀도'라는 새로운 열을 추가하세요.
- 인구 밀도가 높은 순서대로 DataFrame을 정렬하세요.

import pandas as pd
# 1. DataFrame 생성
data = {
'도시': ['서울', '부산', '인천', '대구', '대전'],
'인구': [10000000, 3500000, 3000000, 2500000, 1500000],
'면적': [605, 770, 1063, 884, 539]
}
df = pd.DataFrame(data)
print("DataFrame:\n", df)
# 2. '인구 밀도' 열 추가
df['인구 밀도'] = df['인구'] / df['면적']
print("\n'인구 밀도' 열 추가 후 DataFrame:\n", df)
# 3. 인구 밀도가 높은 순서대로 정렬
df_sorted = df.sort_values(by='인구 밀도', ascending=False)
print("\n인구 밀도 순서대로 정렬된 DataFrame:\n", df_sorted)
예시 문제 4: 기본 데이터 조작
문제:
- 다음 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 학생: ['John', 'Alice', 'Bob', 'Eva', 'Charlie']
- 수학 점수: [85, 92, 78, 90, 88]
- 영어 점수: [78, 95, 80, 85, 92]
- 과학 점수: [89, 94, 76, 88, 90]
- 데이터:
- 각 학생의 평균 점수를 계산하여 '평균 점수' 열을 추가하세요.
- '평균 점수'가 85점 이상인 학생들을 선택하여 출력하세요.
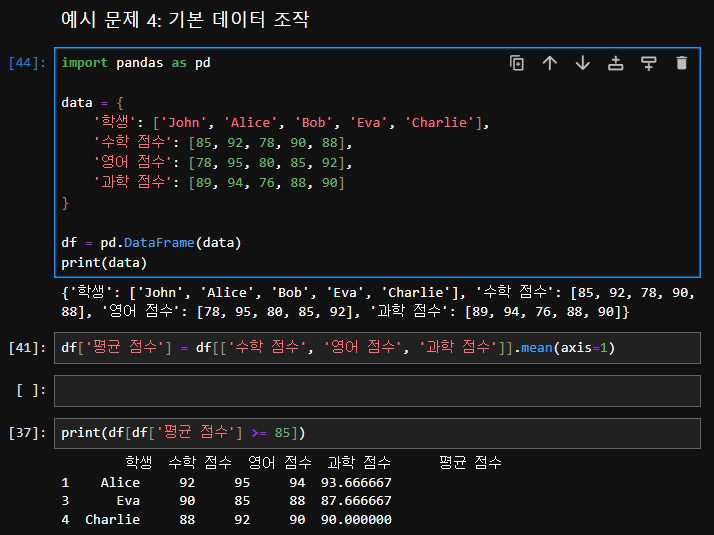
import pandas as pd
# 1. DataFrame 생성
data = {
'학생': ['John', 'Alice', 'Bob', 'Eva', 'Charlie'],
'수학 점수': [85, 92, 78, 90, 88],
'영어 점수': [78, 95, 80, 85, 92],
'과학 점수': [89, 94, 76, 88, 90]
}
df = pd.DataFrame(data)
# 2. '평균 점수' 열 추가
df['평균 점수'] = df[['수학 점수', '영어 점수', '과학 점수']].mean(axis=1)
# 3. '평균 점수'가 85점 이상인 학생 선택
high_achievers = df[df['평균 점수'] >= 85]
print(high_achievers)
*** 추가 공부)
axis=1은 pandas에서 메서드를 사용할 때 행(row)을 따라 연산을 수행하라는 의미입니다.
axis 매개변수는 0과 1의 값을 가질 수 있으며, 각각 열(column)과 행(row)을 나타냅니다.
- axis=0: 열(column)을 따라 연산을 수행합니다. 즉, 각 열의 값들을 기준으로 연산을 수행합니다.
- axis=1: 행(row)을 따라 연산을 수행합니다. 즉, 각 행의 값들을 기준으로 연산을 수행합니다.
예시 문제 5: 데이터 필터링 및 집계
문제:
- 다음 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 제품: ['A', 'B', 'A', 'C', 'B', 'A']
- 가격: [100, 150, 100, 200, 150, 100]
- 수량: [1, 2, 3, 1, 2, 1]
- 지역: ['서울', '부산', '서울', '대구', '부산', '서울']
- 데이터:
- '가격'과 '수량'을 곱하여 각 제품의 '총 판매 금액'을 계산하고 새로운 열로 추가하세요.
- 지역별로 그룹화하여 각 지역의 총 판매 금액 합계를 구하세요.

import pandas as pd
# 1. DataFrame 생성
data = {
'제품': ['A', 'B', 'A', 'C', 'B', 'A'],
'가격': [100, 150, 100, 200, 150, 100],
'수량': [1, 2, 3, 1, 2, 1],
'지역': ['서울', '부산', '서울', '대구', '부산', '서울']
}
df = pd.DataFrame(data)
# 2. '총 판매 금액' 열 추가
df['총 판매 금액'] = df['가격'] * df['수량']
# 3. 지역별 총 판매 금액 합계 구하기
region_sales = df.groupby('지역')['총 판매 금액'].sum()
print(region_sales)
예시 문제 6: 데이터 정렬 및 시각화
문제:
- 다음 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 나라: ['한국', '미국', '중국', '일본', '독일']
- 인구: [51780000, 331000000, 1439323776, 126476461, 83166711]
- GDP: [1693200000000, 21433000000000, 14342900000000, 5065000000000, 3846000000000]
- 데이터:
- '인구' 열을 기준으로 내림차순으로 정렬하세요.
- '나라'와 'GDP' 열만 선택하여 출력하세요.
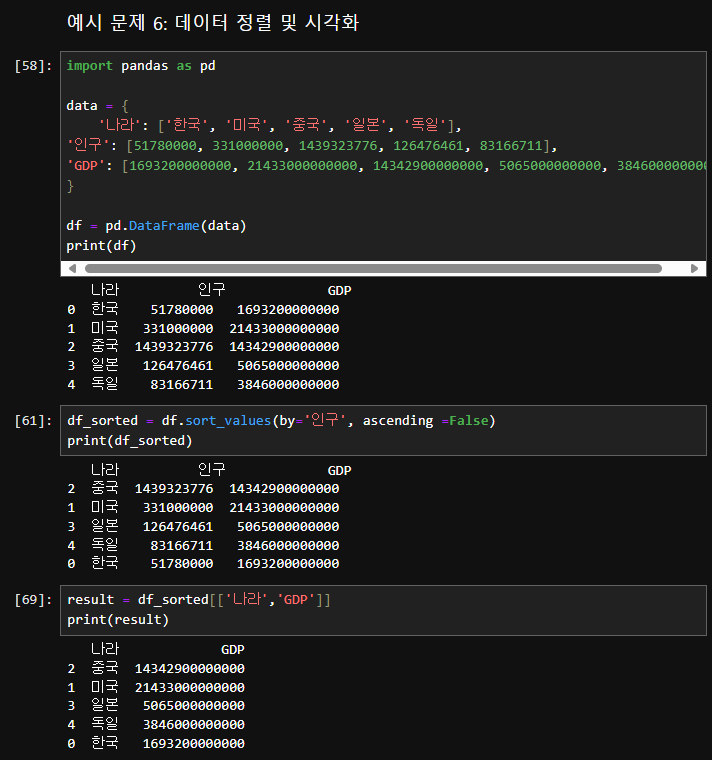
import pandas as pd
# 1. DataFrame 생성
data = {
'나라': ['한국', '미국', '중국', '일본', '독일'],
'인구': [51780000, 331000000, 1439323776, 126476461, 83166711],
'GDP': [1693200000000, 21433000000000, 14342900000000, 5065000000000, 3846000000000]
}
df = pd.DataFrame(data)
# 2. '인구' 열을 기준으로 내림차순 정렬
df_sorted = df.sort_values(by='인구', ascending=False)
# 3. '나라'와 'GDP' 열만 선택하여 출력
result = df_sorted[['나라', 'GDP']]
print(result)
"Python 4) Anaconda prompt ; DataFrame 연습문제 (2)"
"Python 4) Anaconda prompt ; DataFrame 연습문제 (2)"
DataFrame이란?DataFrame은 pandas 라이브러리에서 제공하는 2차원 데이터 구조로, 행(row)과 열(column)로 이루어진 테이블 형태의 데이터를 다루기 위해 사용됩니다. DataFrame은 스프레드시트나 데이터베
game-whisperers.tistory.com
"Python 3) Anaconda prompt 데이터 유형과 구조에 대해 공부하자"
"Python 3) Anaconda prompt 데이터 유형과 구조에 대해 공부하자"
Python 공부하기 데이터 유형 테이터 구조 1. 리스트 (list) 2. 튜플 (tuple) 3. 딕셔너리 (dictionary) 4. 시리즈 (Series) 5. 데이터프레임 (DataFrame) Python에서 데이터 유형(data type)은 변수에 저장할
game-whisperers.tistory.com
'python, anaconda study' 카테고리의 다른 글
| "Python 4) Anaconda prompt ; DataFrame 연습문제 (2)" (0) | 2024.06.22 |
|---|---|
| "Python 3) Anaconda prompt 데이터 유형과 구조에 대해 공부하자" (0) | 2024.06.20 |
| "Python 2) Anaconda prompt 연산자 (산술, 비교, 논리, 비트, 식별 ...)" (0) | 2024.06.18 |
| "Python 1) Anaconda prompt 명령어 (dir / tree / cd / 드라이브 / md / rd ?" (2) | 2024.06.18 |



