DataFrame이란?
DataFrame은 pandas 라이브러리에서 제공하는 2차원 데이터 구조로, 행(row)과 열(column)로 이루어진 테이블 형태의 데이터를 다루기 위해 사용됩니다. DataFrame은 스프레드시트나 데이터베이스 테이블과 유사하며, 다양한 데이터 조작 및 분석 작업에 매우 유용합니다. 각 열은 서로 다른 데이터 타입을 가질 수 있으며, 행과 열 모두에 인덱스를 지정할 수 있습니다.
주요 특징
- 2차원 데이터 구조: 행과 열로 구성된 테이블 형태의 데이터.
- 다양한 데이터 타입 지원: 각 열이 서로 다른 데이터 타입을 가질 수 있음.
- 레이블 인덱싱: 행과 열에 각각 레이블(이름)을 지정할 수 있음.
- 다양한 데이터 조작 기능: 데이터 필터링, 그룹화, 집계, 정렬, 결합 등의 다양한 데이터 처리 기능 제공.
==============
연습문제 1: 기본 DataFrame 생성 및 조작
문제:
- 다음 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 제품: ['노트북', '모니터', '키보드', '마우스', '프린터']
- 가격: [1500000, 300000, 20000, 10000, 200000]
- 수량: [10, 20, 150, 300, 5]
- 데이터:
- 각 제품의 총 가격(가격 * 수량)을 계산하여 '총 가격' 열을 추가하세요.
- '총 가격'이 500,000 이상인 제품들만 선택하여 출력하세요.
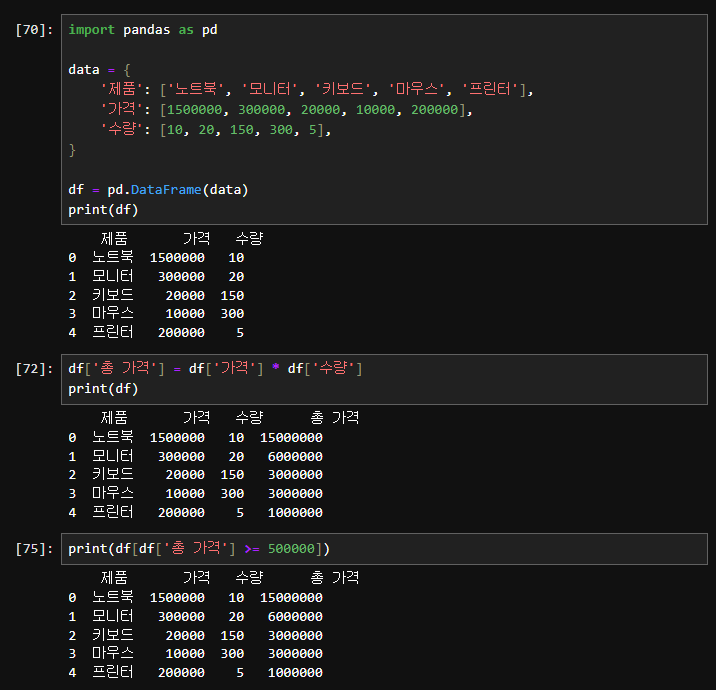
import pandas as pd
# 1. DataFrame 생성
data = {
'제품': ['노트북', '모니터', '키보드', '마우스', '프린터'],
'가격': [1500000, 300000, 20000, 10000, 200000],
'수량': [10, 20, 150, 300, 5]
}
df = pd.DataFrame(data)
# 2. '총 가격' 열 추가
df['총 가격'] = df['가격'] * df['수량']
# 3. '총 가격'이 500,000 이상인 제품 선택
expensive_products = df[df['총 가격'] >= 500000]
print(expensive_products)
연습문제 2: 데이터 필터링 및 그룹화
문제:
- 다음 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 직원: ['Kim', 'Lee', 'Park', 'Choi', 'Jung']
- 부서: ['HR', 'Finance', 'IT', 'IT', 'Finance']
- 급여: [5000000, 6000000, 5500000, 7000000, 4500000]
- 데이터:
- 부서별로 평균 급여를 계산하세요.
- 급여가 5,500,000 이상인 직원들을 선택하여 출력하세요.

import pandas as pd
# 1. DataFrame 생성
data = {
'직원': ['Kim', 'Lee', 'Park', 'Choi', 'Jung'],
'부서': ['HR', 'Finance', 'IT', 'IT', 'Finance'],
'급여': [5000000, 6000000, 5500000, 7000000, 4500000]
}
df = pd.DataFrame(data)
# 2. 부서별 평균 급여 계산
average_salary_by_dept = df.groupby('부서')['급여'].mean()
print(average_salary_by_dept)
# 3. 급여가 5,500,000 이상인 직원 선택
high_salary_employees = df[df['급여'] >= 5500000]
print(high_salary_employees)
연습문제 3: 데이터 정렬 및 선택
문제:
- 다음 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 학생: ['John', 'Alice', 'Bob', 'Eva', 'Charlie']
- 수학 점수: [85, 92, 78, 90, 88]
- 영어 점수: [78, 95, 80, 85, 92]
- 과학 점수: [89, 94, 76, 88, 90]
- 데이터:
- '수학 점수'를 기준으로 내림차순으로 정렬하세요.
- '학생'과 '영어 점수' 열만 선택하여 출력하세요.

import pandas as pd
# 1. DataFrame 생성
data = {
'학생': ['John', 'Alice', 'Bob', 'Eva', 'Charlie'],
'수학 점수': [85, 92, 78, 90, 88],
'영어 점수': [78, 95, 80, 85, 92],
'과학 점수': [89, 94, 76, 88, 90]
}
df = pd.DataFrame(data)
# 2. '수학 점수'를 기준으로 내림차순 정렬
df_sorted = df.sort_values(by='수학 점수', ascending=False)
# 3. '학생'과 '영어 점수' 열 선택
result = df_sorted[['학생', '영어 점수']]
print(result)
연습문제 4: 데이터 추가 및 통계 분석
문제:
- 다음 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 제품: ['TV', '냉장고', '세탁기', '에어컨', '청소기']
- 가격: [1000000, 1500000, 800000, 1200000, 200000]
- 판매량: [50, 30, 100, 20, 150]
- 데이터:
- 각 제품의 총 매출(가격 * 판매량)을 계산하여 '총 매출' 열을 추가하세요.
- '총 매출'의 평균과 표준편차를 계산하세요.
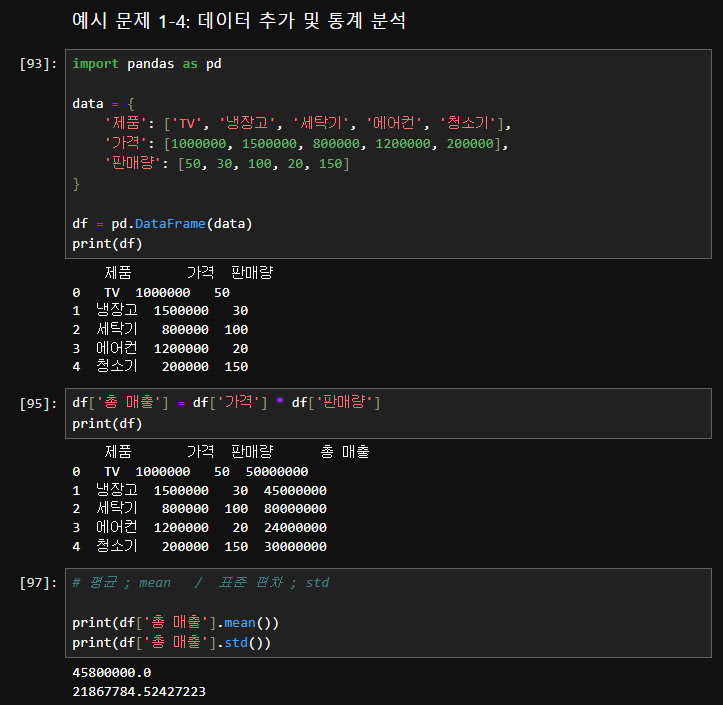
import pandas as pd
# 1. DataFrame 생성
data = {
'제품': ['TV', '냉장고', '세탁기', '에어컨', '청소기'],
'가격': [1000000, 1500000, 800000, 1200000, 200000],
'판매량': [50, 30, 100, 20, 150]
}
df = pd.DataFrame(data)
# 2. '총 매출' 열 추가
df['총 매출'] = df['가격'] * df['판매량']
# 3. '총 매출'의 평균과 표준편차 계산
average_sales = df['총 매출'].mean()
std_sales = df['총 매출'].std()
print("총 매출의 평균:", average_sales)
print("총 매출의 표준편차:", std_sales)
연습문제 5: 날짜 데이터를 활용한 분석
문제:
- 다음 데이터를 사용하여 DataFrame을 생성하세요.
- 데이터:
- 날짜: ['2024-01-01', '2024-01-02', '2024-01-03', '2024-01-04', '2024-01-05']
- 온도: [5, 3, 0, -2, 1]
- 강수량: [0, 0, 5, 10, 0]
- 데이터:
- 날짜 데이터를 datetime 형식으로 변환하세요.
- 일일 온도의 평균을 계산하세요.
- 강수량이 5 이상인 날의 데이터를 선택하여 출력하세요.

import pandas as pd
# 1. DataFrame 생성
data = {
'날짜': ['2024-01-01', '2024-01-02', '2024-01-03', '2024-01-04', '2024-01-05'],
'온도': [5, 3, 0, -2, 1],
'강수량': [0, 0, 5, 10, 0]
}
df = pd.DataFrame(data)
# 2. 날짜 데이터를 datetime 형식으로 변환
df['날짜'] = pd.to_datetime(df['날짜'])
# 3. 일일 온도의 평균 계산
average_temperature = df['온도'].mean()
print("일일 온도의 평균:", average_temperature)
# 4. 강수량이 5 이상인 날의 데이터 선택
rainy_days = df[df['강수량'] >= 5]
print(rainy_days)
연습문제 6: 데이터 결합 및 중복 제거
문제:
- 다음 두 개의 데이터를 사용하여 각각 DataFrame을 생성하세요.
- 데이터 1:
- 이름: ['Kim', 'Lee', 'Park']
- 점수: [90, 85, 95]
- 데이터 2:
- 이름: ['Choi', 'Jung', 'Kim']
- 점수: [80, 75, 90]
- 데이터 1:
- 두 DataFrame을 결합하여 하나의 DataFrame을 만드세요.
- 중복된 이름을 제거하고, 중복된 경우 첫 번째 데이터만 남겨두세요.

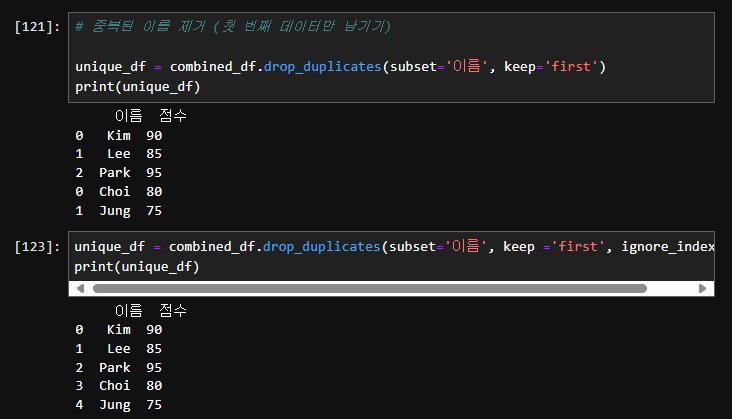
** pd.concat 함수는 기본적으로 인덱스를 유지하므로,
인덱스가 중복되어 나타나는 것을 볼 수 있습니다.
인덱스를 재설정하고 싶다면 ignore_index=True 옵션을 사용할 수 있습니다.

"Python 4) Anaconda prompt ; DataFrame 연습문제 (1)"
"Python 4) Anaconda prompt ; DataFrame 연습문제 (1)"
DataFrame은 파이썬의 데이터 분석 라이브러리인 pandas에서 제공하는 2차원, 테이블 형식의 자료 구조입니다. DataFrame은 행(row)과 열(column)로 구성되며, 각 열은 서로 다른 데이터 타입을 가질 수 있
game-whisperers.tistory.com
'python, anaconda study' 카테고리의 다른 글
| "Python 4) Anaconda prompt ; DataFrame 연습문제 (1)" (0) | 2024.06.22 |
|---|---|
| "Python 3) Anaconda prompt 데이터 유형과 구조에 대해 공부하자" (0) | 2024.06.20 |
| "Python 2) Anaconda prompt 연산자 (산술, 비교, 논리, 비트, 식별 ...)" (0) | 2024.06.18 |
| "Python 1) Anaconda prompt 명령어 (dir / tree / cd / 드라이브 / md / rd ?" (2) | 2024.06.18 |



